Power BIのDAX関数に比較的最近に追加されたoffset関数。
同じタイミングで追加されたindex関数、window関数と合わせてこれまでSQLでは容易にできていて、Power BIでは簡単に実装できなかったところに手が届くようになりました。
SQLのWindow関数と似ているところがあり、取り扱いが難しいのでこちらで使い方を紹介していきます。
index関数、window関数の使い方について解説した記事はこちら。


offset関数
Microsoftの公式ページではoffset関数は下記のように定義されています。
同じテーブル内で、指定されたオフセットだけ “現在の行” より前または後にある 1 行を返します
関数としてはこちらになります。
OFFSET ( <delta>[, <relation>][, <orderBy>][, <blanks>][, <partitionBy>][, <matchBy>] )
delta
deltaはデータを取得する場所を指定します。
現在の行より前の値であれば負の値、後ろの値であれば正の値を指定します。
前の行を指定したければ-1になります。
relation
返される出力のもととなるテーブルを指定します。
orderBy
各パーティションの並び方法を指定します。
昇順、降順の指定も可能です。
blanks
空白値の処理を指定するところですが現在サポートされている値は DEFAULT のみとなります。
数値が空白の場合、値の順番は 0 と負の値の間になります。
文字列が空白の場合は、空の文字列を含めてすべての文字列の前に並べ替えられます。
partitionBy
パーティションを指定します。
SQLのWindow関数のように処理したい塊を指定できます。
matchBy
データの照合方法を指定します。
offset関数の使い方
ここまではoffset関数の説明でしたが、この説明だけではわかりづらいので実際に挙動を見ていきます。
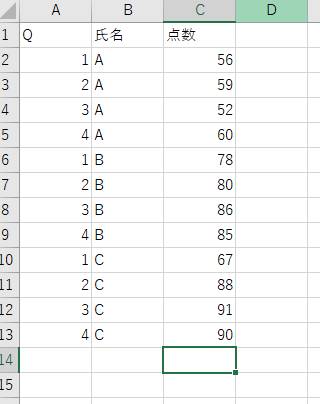
まずは簡単にデータを準備しました。
QごとにAさん、Bさん、Cさんのテストの点数をまとめたデータになります。
まずは各メンバーごと前回の点数を表示します。
前回の点数と比較してどうかといったシチュエーションはよくあると思います。
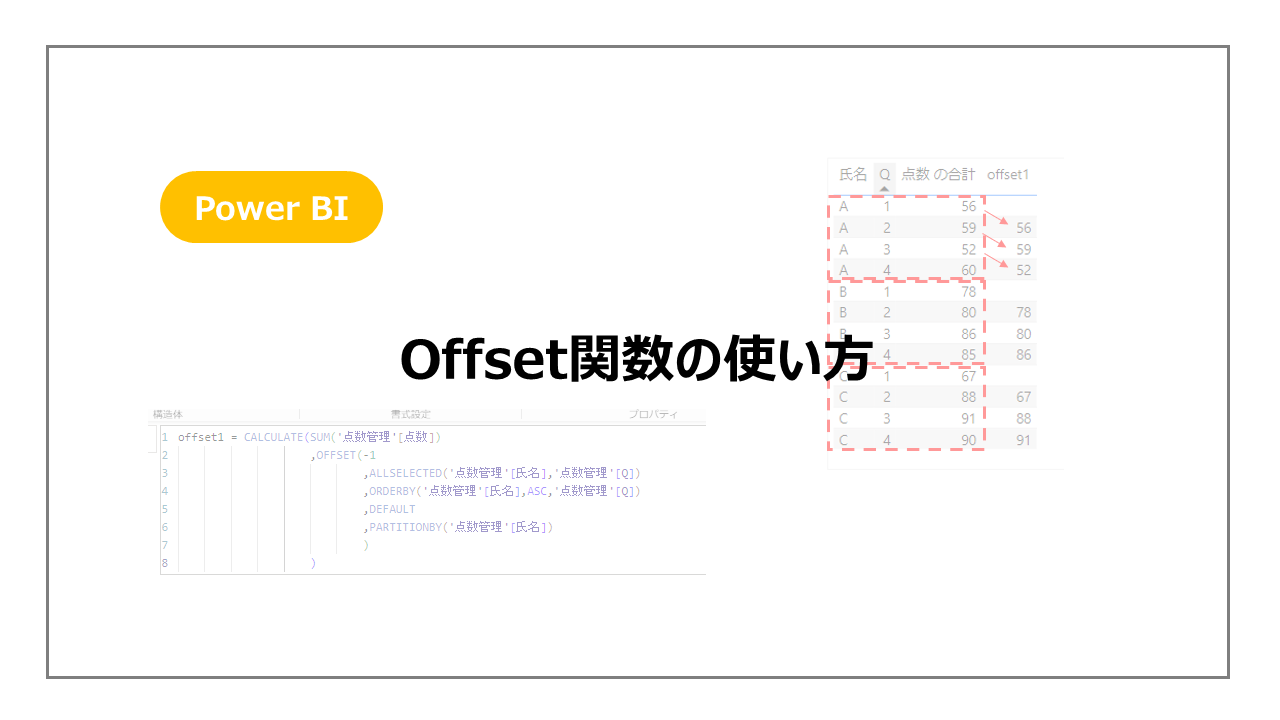
新しいメジャーを作成し、下記のようなDAX関数を作成します。

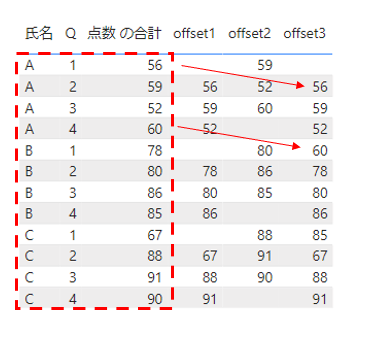
これを実際に表示させてみるとこちらになります。
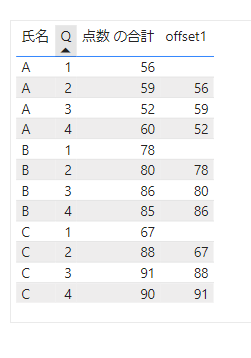
氏名ごとの単位でパーティションを作り、氏名、Qでソートし、前の行の点数が取得されていることがわかります。
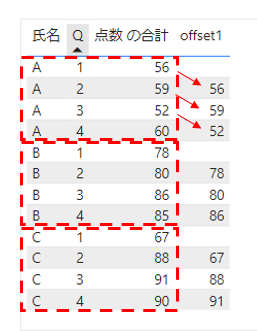
続いて少しDAX関数を変更してみましょう。
取得する行を-1→1に変更します。
こちらを表示してみます。
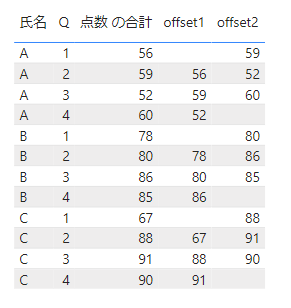
次の行の点数が取得されていることがわかります。
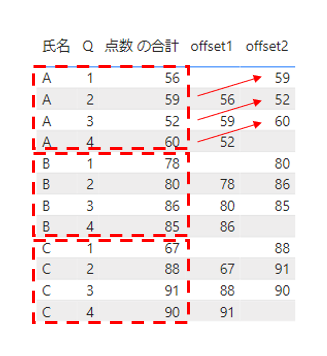
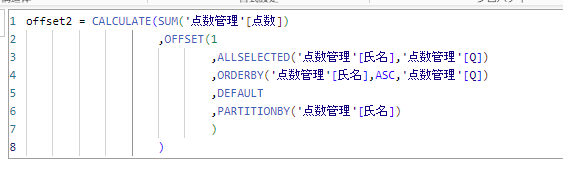
最後にパーティション部分を変更してみます。
パーティションは省力可能ですので、省略したDAX関数がこちらです。
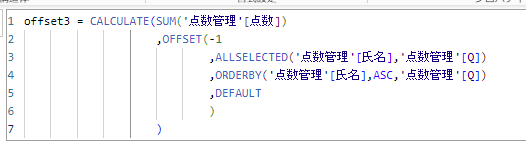
表示した結果がこちらになります。
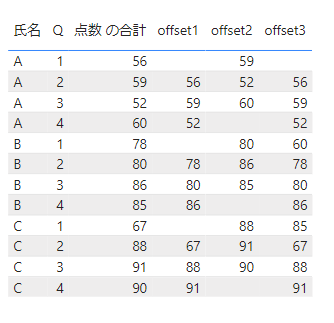
パーティション関係なく、前の行の点数が表示されていることがわかります。
他の人の点数が入っているのでこれをこのまま使うことは少ないですかね。
まとめ:Power BI index関数の使い方
Power BIのoffset関数の使い方を紹介しました。
指定するパラメータは多いですが、これまでSQLでできていてPower BIでは実装が難しかったことが簡単にできるようになっています。
可視化、分析の幅がより広がるのでぜひおさえてください!
Power BIの機能を手広く学習していきたい方には書籍やUdemyがおすすめです。