Power BIのDAX関数に比較的最近に追加されたindex関数。
同じタイミングで追加されたoffset関数、window関数と合わせてこれまでSQLでは容易にできていて、Power BIでは簡単に実装できなかったところに手が届くようになりました。
SQLのWindow関数と似ているところがあり、取り扱いが難しいのでこちらで使い方を紹介していきます。
index関数,offset関数の使い方について解説した記事はこちら。


index関数
Microsoftの公式ページではindex関数は下記のように定義されています。
指定されたパーティションを指定された順序で並べ替えて、絶対位置 (position パラメーターで指定) にある行を返します
関数としてはこちらになります。
INDEX(<position>[, <relation>][, <orderBy>][, <blanks>][, <partitionBy>][, <matchBy>])
Position
Positionは取得するデータの位置になります。
最初の行を取得したいときは1を、最後の行を取得したいときは-1を指定します。
relation
返される出力のもととなるテーブルを指定します。
orderBy
各パーティションの並び方法を指定します。
昇順、降順の指定も可能です。
blanks
空白値の処理を指定するところですが現在サポートされている値は DEFAULT のみとなります。
数値が空白の場合、値の順番は 0 と負の値の間になります。
文字列が空白の場合は、空の文字列を含めてすべての文字列の前に並べ替えられます。
partitionBy
パーティションを指定します。
SQLのWindow関数のように処理したい塊を指定できます。
matchBy
データの照合方法を指定します。
index関数の使い方
ここまではindex関数の説明でしたが、この説明だけではわかりづらいので実際に挙動を見ていきます。
まずは簡単にデータを準備しました。
四半期(クォーター)ごとにAさん、Bさん、Cさんのテストの点数をまとめたデータになります。
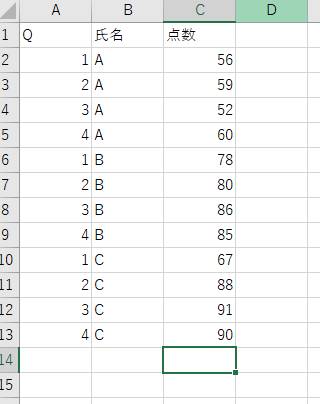
まずは各メンバーごとに1Qの点数を取得する表示するといったことを行っていきます。
1Qの点数といった一番最初のデータと比較してどうかといったシチュエーションはよくあると思います。
新しいメジャーを作成し、下記のようなDAX関数を作成します。
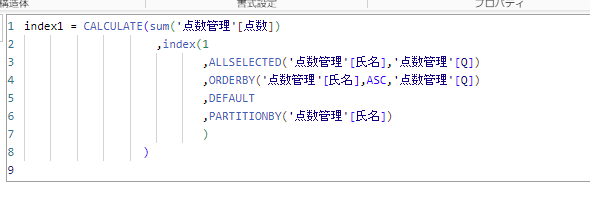
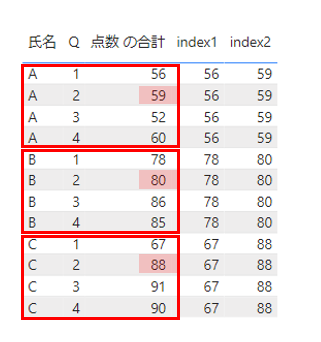
これを実際に表示させてみるとこちらになります。
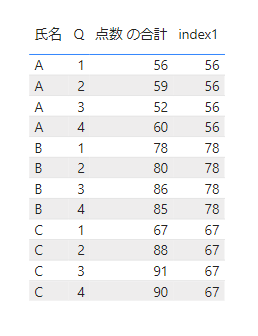
氏名ごとの単位でパーティションを作り、氏名、Qでソートし、最初の行を取得する処理となっています。
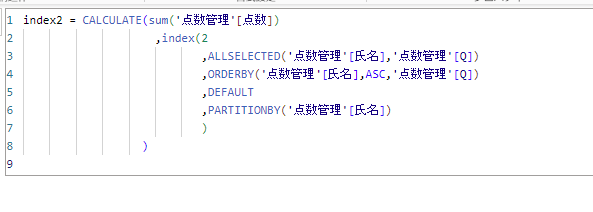
続いて少しDAX関数を変更してみましょう。
取得する行を1→2に変更します。
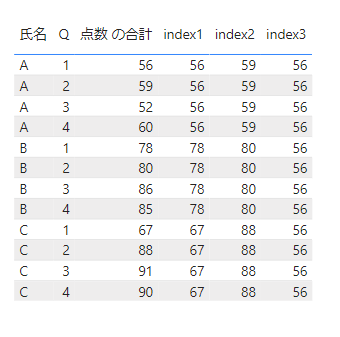
テーブルに表示するとこちらになります。
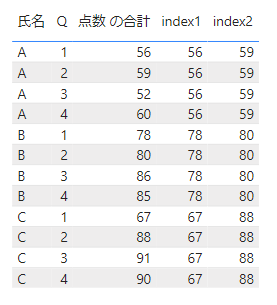
2行目のデータが表示されていることがわかります。
最後にパーティション部分を変更してみます。
パーティションは省力可能ですので、省略したDAX関数がこちらです。
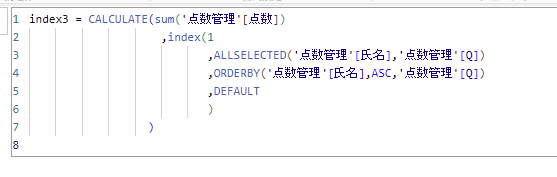
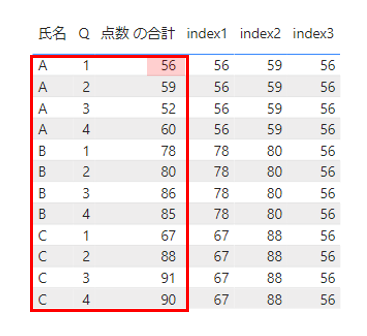
テーブルに表示するとこちらになります。
パーティションとしては全体で一つのパーティションという扱いになるためその先頭行Aさんの1Qの値が表示されることになります。
まとめ:Power BI index関数の使い方
Power BIのindex関数の使い方を紹介しました。
指定するパラメータは多いですが、これまでSQLでできていてPower BIでは実装が難しかったことが簡単にできるようになっています。
可視化、分析の幅がより広がるのでぜひおさえてください!
Power BIの機能を手広く学習していきたい方には書籍やUdemyがおすすめです。